Jeszcze kilka lat temu mogło się wydawać, że rozwój modeli językowych będzie oznaczał globalną unifikację jakości generowanych treści. Dziś wiemy, że rzeczywistość jest bardziej złożona – szczególnie w przypadku języków takich jak polski. Test porównawczy modeli LLM pokazuje wyraźnie: nie wszystkie AI radzą sobie równie dobrze poza językiem angielskim.

Polski – trudny sprawdzian dla AI
Większość najpopularniejszych modeli AI powstaje w Stanach Zjednoczonych lub Chinach i trenowana jest głównie na danych anglojęzycznych. W efekcie, gdy muszą operować w języku polskim, napotykają na istotne bariery – od złożonej fleksji po kontekst kulturowy.
Test przeprowadzony przez Marka Jeleśniańskiego, założyciela i CEO firmy Oxido, eksperta i szkoleniowca w zakresie korzystania z AI, objął kilkanaście modeli, w tym m.in. model GPT od OpenAI, Gemini od Google, Claude stworzony przez Anthropic, a także polskiego Bielika. Celem testu było sprawdzenie, jak te modele radzą sobie z generowaniem treści po polsku w warunkach, w jakich korzystamy z AI najczęściej, czyli przez interfejs webowy. Każdy z nich otrzymał identyczny zestaw zadań – od korekty tekstów, przez analizę faktów, aż po tworzenie treści marketingowych i humorystycznych.
„Pomoże” czy „Pomorze”?
Jednym z najbardziej wymownych przykładów były zadania językowe wymagające precyzji. Modele miały rozpoznać poprawne formy wyrazów i uzasadnić wybór. Okazało się, że nawet drobne różnice – jak wielka litera w słowie „Pomorze” – potrafią zmylić AI.
Część modeli uznawała błędną formę „pomorze” za poprawną, sugerując się znaczeniem zamiast ortografią. To pokazuje, że modele często „rozumieją” sens wypowiedzi, ale nie zawsze radzą sobie z formalną poprawnością językową.
Który model LLM wypadł najlepiej w testach?
W zależności od zadania liderzy się zmieniali:
- Korekta tekstu zawierającego liczne błędy językowe: najlepiej poradził sobie Llama firmy Meta, wyprzedzając m.in. polskie modele, w tym Bielika. – Korekta trudnego tekstu w języku polskim pozostaje dla modeli językowych stosunkowo wymagającym zadaniem – podkreśla Marek Jeleśniański.
- Zadania językowe (wskazanie poprawnej formy słowa): W tym zadaniu Bielik znalazł się wśród najwyżej ocenionych modeli, wyprzedzając m.in. Groka 4.2, Gemini 3.1 Pro oraz DeepSeek V3.2.
- Marketing (przygotowanie prezentacji dotyczącej kampanii promocyjnej dla lokalnego produktu): Zwyciężył Qwen, chińskiej firmy Alibaba. Zbliżone rezultaty osiągnęły także modele Mistral, Gemini, Grok, GPT-5.2 oraz Llama.
- Podatki (wskazanie właściwych stawek VAT na podstawie polskich przepisów podatkowych w dwóch opisanych sytuacjach biznesowych): Najwyższy wynik (9,5) uzyskały chiński Qwen 3.5 Plus oraz amerykański ChatGPT, minimalnie mniej polski Bielik – 9,4. Częściowo nieprawidłowych odpowiedzi udzieliły modele DeepSeek i Mistral, natomiast w przypadku EuroLLM doszło do halucynacji i model wygenerował nieistniejące ulgi podatkowe.
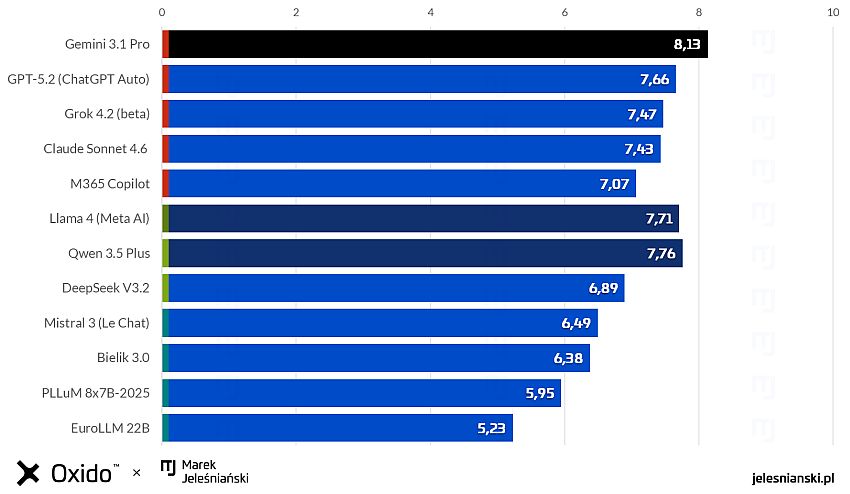
Wyniki testu pokazują, że różnice między systemami pojawiają się głównie w bardziej szczegółowych aspektach, takich jak sposób interpretacji poleceń, precyzja odpowiedzi, kreatywność czy zdolność do pracy w określonym kontekście językowym i kulturowym.
Większość modeli radziła sobie dobrze, ale pojawiały się błędy, takie jak: błędna interpretacja poleceń, „halucynacje” (np. nieistniejące ulgi podatkowe) czy różnice w jakości strategii marketingowych. Wnioski? Nie istnieje jeden „najlepszy” model – skuteczność zależy od kontekstu zastosowania.
„Modele LLM są całkiem niezłe w informowaniu nas o faktach, natomiast mają problem ze zrozumieniem kontekstu społeczno-kulturowego”, mówi Marek Jeleśniański i dodaje, że kryterium, gdzie wszystkie modele poległy, był polski humor 🙂
Najlepsi są najwięksi, ale lokalne modele z potencjałem
Czołówkę rankingu zdominowały modele rozwijane przez globalnych gigantów technologicznych z USA i Chin. Jednocześnie coraz większe znaczenie mają rozwiązania, które można wdrożyć lokalnie – szczególnie w kontekście bezpieczeństwa danych.
Warto też zwrócić uwagę na ekosystem narzędzi. Nie liczy się tylko model, ale także: integracje (np. z pakietami biurowymi), możliwości personalizacji oraz środowisko pracy użytkownika.
Europa i Polska – gdzie jesteśmy?
Choć w Europie powstają własne modele językowe, konkurencja z USA i Chin pozostaje ogromnym wyzwaniem. Kluczowe będą inwestycje w rozwój AI, dostęp do danych treningowych oraz stabilne warunki dla firm technologicznych. Polskie modele – takie jak Bielik – pokazują potencjał, ale droga do globalnej czołówki wciąż jest długa.
Test jasno pokazuje, że choć modele LLM osiągają imponujące wyniki, to język polski nadal stanowi dla nich wymagające środowisko. Różnice w jakości odpowiedzi, szczególnie w detalach językowych, mogą mieć znaczenie w praktycznych zastosowaniach – od marketingu po analizę prawną.
Pełny raport z badań i ranking modeli językowych pod adresem: https://jelesnianski.pl/badania-llm/
(grafika tytułowa wygenerowana przez ChatGPT)

